
In this article, you will learn how the serverless computing model can be achieved using Microsoft’s cloud technologies and how it can facilitate application development and deployment processes. To show how the serverless architecture works, let’s take a look at a real-world scenario – implementing a data-sharing service.

Implementing a data sharing service – the old approach
Not more than ten years ago, if an IT professional was asked to develop a solution that would enable file sharing with customers, it required a few standard steps. First, you had to buy and prepare a server with enough storage space. The next step was to implement a secure software solution for data exchange, secure the entire network and, after confirming that there were no security breaches, carefully open the new service to the outside world. But that’s only part of the process. In order for everything to work, a suitable client application had to be made available. Staff had to be trained on the new system, and then instructions for use had to be made available to customers. All of this turned into a huge project and you had to wait a long time to see the results. what about now Has the advent of cloud computing with execution models like serverless really changed the way you work?
The modern approach
The idea behind the concept known as serverless computing is simple: instead of managing the server architecture and other application-related resources yourself, you can now delegate these tasks to a cloud provider. As a result, you no longer have to worry about infrastructure maintenance, the system is fully scalable (or elastic, as some people call it) and secure (most cloud-based services have top-notch security solutions), and the overall implementation is incomparably faster and easier. Application functionalities can also be moved to the cloud (the concept is known as Function as a Service or FaaS), further simplifying the development process.
So what is the best way to implement serverless architecture in our real case example, data sharing? When adopting the serverless model, it’s a good idea to leverage the resources and knowledge your organization already has. This reduces the time and cost of purchasing new applications and devices, and adoption is much easier as no additional staff training is required.
For this example, I assume that the company already uses Microsoft Azure, Office 365 and related services like SharePoint. This is what the implementation of data sharing can look like when you combine these resources with the serverless cloud technologies that come with Microsoft Azure:
- In SharePoint Online, create a new folder for the files you want to share.
- In the Azure cloud, you prepare computing space via a service such as Azure blob storage along with an appropriate retention policy (e.g. remove files after 7 days).
- Use Azure Logic Appscreate an automated process that:
- Activated when there is a new file in the previously specified SharePoint Online folder.
- Downloads the new file.
- Places the file in the predefined location in Azure Blob Storage.
- Removes the file from SharePoint Online.
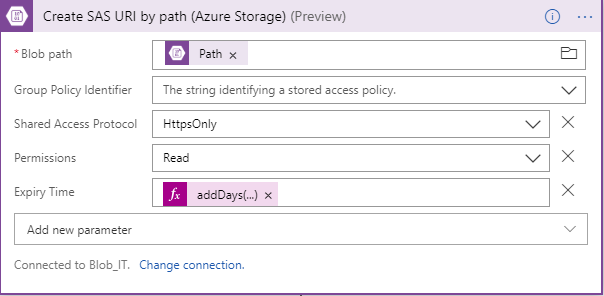
- Grants access to this file via the Shared Access Signatures (SAS). It is also possible to restrict access to specific IP addresses, specific time periods, permissions, etc.
- Sends an email to the owner (the user who originally uploaded the file to SharePoint Online) with a link to the file and an email template for the end customer (end user).
This is how the processing flow in Azure Logic Apps might look like:
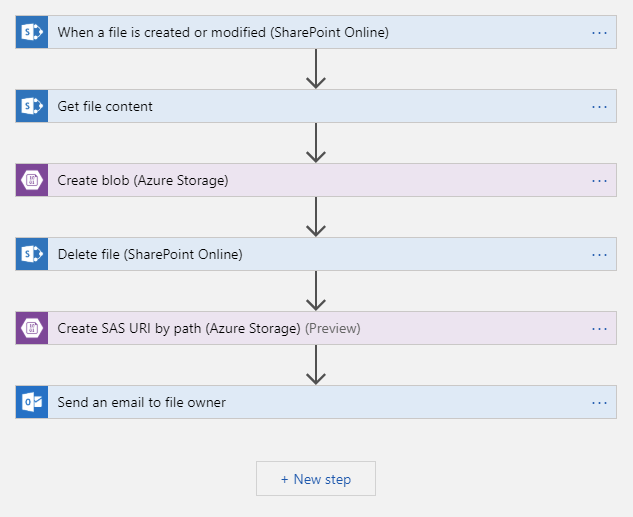
In a relatively short time you get a simple solution that can be reused by different teams. The solution is immediately available and does not incur any costs if it is not used. With this approach, files are shared one at a time; If you have multiple files to share, archive them into a single ZIP file before uploading. For security reasons, files are only visible to those who uploaded them (no other team members can access them) and those who have permission to download them.
configuration in detail
Now let’s take a closer look at the possible configuration:
- You need to specify the intervals, ie how often you want to detect the changes in the SharePoint library.
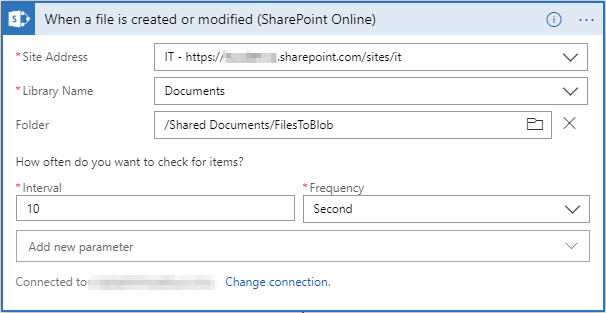
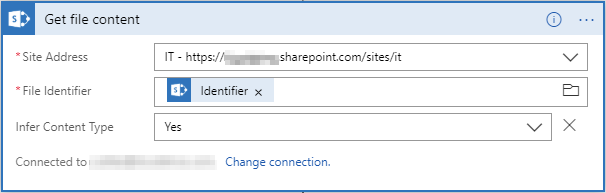
- Then configure the content download.
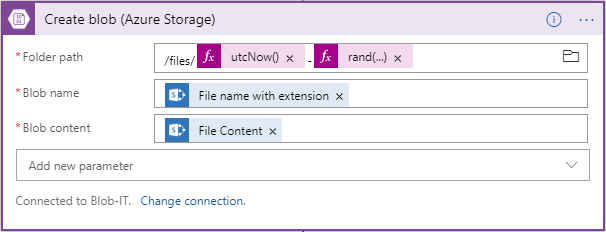
- When configuring file upload to Azure, it’s a good practice to create a unique name for each file or folder that will serve as storage.
- Configure how files are removed from SharePoint Online.
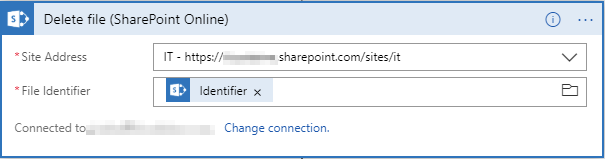
- Create Shared Access Signatures (SAS).
- The final step is to configure how an email is sent to the person who uploaded the file to SharePoint Online.
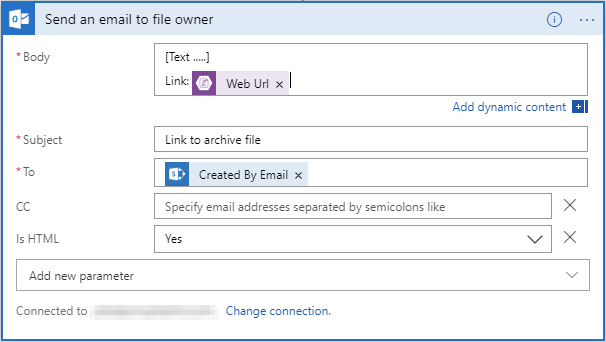
The final result
As you can see, implementing a data sharing service using the features available in the Azure cloud was pretty quick. The solution automatically scales and adapts to increasing loads, so you don’t have to worry about running out of space. Additionally, it doesn’t require a startup budget (assuming you’re already using the Microsoft solutions outlined) and you only pay for the actual time you’re using your data. This means: If the service is not used, you pay nothing (usage-based billing).
Does that mean that all projects can be handled this way? Of course not. Even the serverless model has its own weaknesses and limitations: cold starts after periods of inactivity, increasing costs with increasing use or difficulties in debugging. Some other limitations may depend on the cloud provider of your choice.
Still, even in its early days, the serverless computing approach is certainly worth considering and can bring real benefits in certain scenarios. And with the rapid development of cloud technologies, the demise of traditional server-based architecture seems closer than ever.
Learn more
If you want to dive deeper, here are some resources related to the Microsoft technologies mentioned in the article:

